試験の準備方法-認定するAI-300試験攻略試験-正確的なAI-300独学書籍
Wiki Article
大量の時間と金銭をかかるのに比べて、正しい仕方は肝心なことです。もしあなたはMicrosoft AI-300試験に準備しているなら、あんたのための整理される備考資料はあなたにとって最善のオプションです。我々の目標はあなたに試験にうまく合格させることです。弊社の誠意を信じてもらいたいし、Microsoft AI-300試験2成功するのを祈って願います。
我々の商品の質量を保証するために、専門家たちは商品の開発を研修しています。過去の試験のデータを基づいて、AI-300問題集を開発しています。現在でも、問題集の更新に働いています。複数の更新を通して、今の的中率高いAI-300問題集になりました。我々のAI-300問題集で試験に合格することができると信じています。
試験の準備方法-最新のAI-300試験攻略試験-検証するAI-300独学書籍
Microsoft認証試験を受かるかどうかが人生の重要な変化に関連することを、受験生はみんなよく知っています。Fast2testは低い価格で高品質の迫真のAI-300問題を受験生に提供して差し上げます。Fast2testの製品もコスト効率が良く、一年間の無料更新サービスを提供しています。当社のAI-300認定トレーニングの材料は、すぐに入手できます。当社のサイトは答案ダンプのリーディングプロバイダーで、あなたが利用したい最新かつ最正確のAI-300試験認定トレーニング材料、いわゆる試験問題と解答を提供しています。
Microsoft Operationalizing Machine Learning and Generative AI Solutions 認定 AI-300 試験問題 (Q32-Q37):
質問 # 32
Hotspot Question
A machine learning model is deployed to production in Azure Machine Learning and is actively serving predictions for a business application. The model was trained by using a historical dataset that represented expected input patterns at the time of deployment.
The team working on the model must ensure the following:
- Changes in input data distribution are detected.
- Appropriate actions are triggered when predefined thresholds are
exceeded.
You need to configure monitoring to meet the requirements.
Which configuration should you use for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.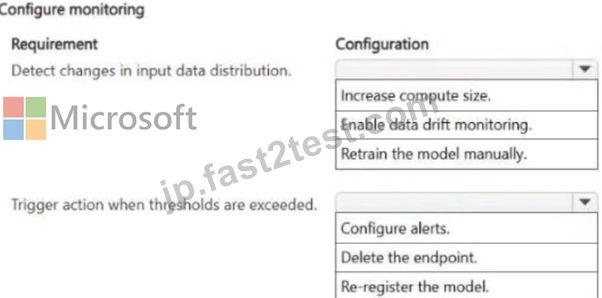
正解:
解説: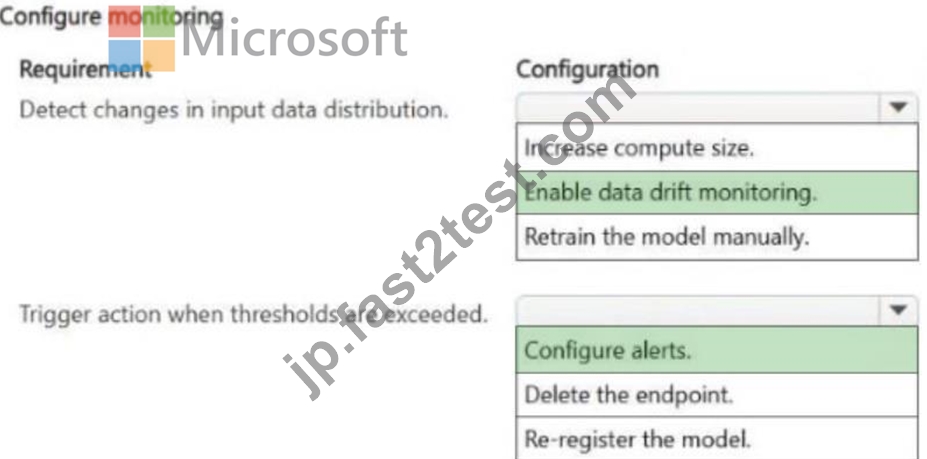
質問 # 33
Drag and Drop Question
An organization operates a generative AI application in production by using Microsoft Foundry.
The application serves live user traffic and is updated by a data scientist team regularly as prompts and models evolve.
The application intermittently times out during production use, which requires ongoing visibility into runtime behavior.
The team must also validate model quality and safety before releasing new updates to avoid introducing regressions.
You need to apply the correct mechanisms for continuous runtime monitoring and for release time validation.
Which mechanisms should you use for each requirement? To answer, move the appropriate mechanisms to the correct requirements. You may use each mechanism once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
正解:
解説:
質問 # 34
A team trains an MLflow model that scores customer churn risk. The model will be consumed by different downstream systems.
One system requests predictions synchronously during customer interactions.
Another system submits files containing millions of records for scheduled scoring.
You need to deploy the model by using managed inference options that match each usage pattern.
Which option should you use for each usage pattern? To answer, select the appropriate options in the answer area . NOTE: Each correct selection is worth one point.
正解:
解説:
Explanation:
A system requesting predictions synchronously during customer interactions needs sub-second responses, while a system submitting files with millions of records can tolerate minutes of processing time. For real-time synchronous serving, a Managed Online Endpoint provisions a persistent always-on container behind an HTTPS REST endpoint that returns predictions within milliseconds. For large-batch asynchronous scoring, a Batch Endpoint accepts a data asset input, distributes scoring across a compute cluster, and writes results back to storage. Online endpoints support auto-scaling based on request volume and traffic splitting. Batch endpoints are invoked on-demand or on a schedule, automatically provisioning and de-provisioning compute, keeping costs low for intermittent large jobs. Each deployment type is purpose-built for its usage pattern and should not be swapped.
Microsoft Learn Reference Topic: Deploy and score models with managed online endpoints and batch endpoints - Azure Machine Learning
質問 # 35
Case Study 1 - Fabrikam Inc.
Background
Fabrikam Inc. is a mid-sized healthcare analytics company that provides population health dashboards and predictive insights to regional hospital systems across the United States.
Fabrikam Inc. customers rely on near real time analytics to monitor patient flow, staffing needs, and readmission risks. They use multiple traditional forecasting machine learning models for predictions.
Fabrikam Inc. has an established copyright footprint. The company uses Jupyter Notebooks that run on a local server as the primary development environment. The data science team is experiencing scalability, asset management and code management issues with the current development platform. Fabrikam Inc. plans to migrate to a cloud-based development environment to mitigate the issues.
Additionally, the company plans to implement a Retrieval-Augmented Generation (RAG)-based chat application for client support. Leadership requires the application to be developed and deployed with a low operational risk.
Current Environment
Fabrikam Inc. operates a single Azure subscription that has the following components:
* Azure Data Lake Storage Gen2 that contains de-identified clinical and operational datasets
* Azure AI Search indexing curated analytical documents and reference materials
* A small set of Python-based training scripts maintained by data scientists
* Azure OpenAI Service with deployed foundational models
* A Microsoft Foundry resource for building a RAG-based solution
Evaluation data has manually defined expected responses.
The current challenges faced by the data science team include the following:
* Model training jobs are run manually from notebooks.
* Experiment tracking is inconsistent
* Model versions are registered without standardized metadata.
* Deployment is performed manually by data scientists, with limited rollback capability.
* The team has no standardized evaluation process for generative AI outputs.
The environment currently allows public network access. Authentication relies on user accounts rather than managed identities. Compute targets are manually created and shared across experiments. This has led to resource contention during peak usage.
Business Requirements
Fabrikam Inc. has the following business requirements for the modernization initiative:
* Provide a conversational interface that answers analytics questions by using internal documents and datasets.
* Ensure that sensitive healthcare-related data is not exposed outside the Fabrikam Inc. Azure tenant.
* Enable repeatable and auditable model training and deployment processes.
* Support experimentation to compare prompt strategies and fine-tuned models.
* Align the model with the ranked preferences and optimize behavior for the long term.
* Minimize disruption to existing analytics workloads during rollout.
Technical Requirements
To support the business goals, Fabrikam Inc. identifies these technical requirements:
* Use Azure Machine Learning workspaces to centrally manage data assets, models, and environments.
* Implement experiment tracking and model versioning for all training jobs.
* Orchestrate training and evaluation by using pipelines rather than manually running notebooks.
* Deploy traditional machine learning models with support for staged rollout and rollback.
* Improve RAG-based solution output quality.
* Use the existing evaluation datasets that are based on real data with input-output pairs.
* Apply advanced fine-tuning techniques only when prompt engineering is insufficient Issues and Constraints Fabrikam Inc. must comply with internal security policies that require the company to restrict network access and avoid long-lived secrets. The data science team has limited Azure DevOps experience, so solutions must favor managed services and automation over custom infrastructure.
Cost predictability is important. Leadership prefers serverless or managed compute options where possible but is willing to approve dedicated compute for stable production workloads.
Problem Statement
Fabrikam Inc. must design and implement an Azure-based AI operations solution that enables reliable training, evaluation, deployment, and iteration of generative AI models. The solution must support experimentation and gradual rollout while ensuring governance, security, and operational stability. The data science and platform teams must collaborate to deliver this solution by using Azure Machine Learning and Microsoft Foundry capabilities.
You need to standardize how Fabrikam Inc. manages machine learning assets. Which action should you perform first?
- A. Deploy a managed online endpoint.
- B. Create a new Microsoft Foundry project.
- C. Register assets in the Azure Machine Learning registry.
- D. Create a shared Azure Machine Learning workspace.
正解:D
解説:
Scenario: To support the business goals, Fabrikam Inc. identifies these technical requirements:
Use Azure Machine Learning workspaces to centrally manage data assets, models, and environments.
To centrally manage data assets, models, and environments across multiple Azure Machine Learning workspaces, you should Create a shared Azure Machine Learning workspace first.
The workspace serves as the top-level resource for your machine learning activities, providing a centralized place to view and manage the artifacts you create. While Registries are used to share assets (like models and environments) across existing workspaces, you must have a workspace as a prerequisite to create or use those assets in a project context.
Key Management Options
Azure provides several ways to organize and centralize your machine learning operations:
Shared Workspace: The primary container for managing data, compute, and experiments within a project team.
Registries: Used specifically for MLOps to decouple assets from specific workspaces, allowing them to be promoted through development, test, and production environments.
Hub Workspaces: A newer feature that groups multiple project workspaces under a single "hub" to share security settings, connections, and compute resources.
Reference:
https://docs.azure.cn/en-us/machine-learning/concept-workspace
質問 # 36
A data science team completes multiple training runs within an experiment by using MLflow.
The team wants to store a selected model in Azure Machine Learning so that it can be versioned and deployed later.
The model must be versioned centrally for reuse across environments.
You need to version the trained model.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point. Choose two .
- A. Register the model in the Azure Machine Learning workspace.
- B. Tag the training experiment with a name.
- C. Locate and capture the model artifacts from the outputs of the training run.
- D. Export the model files to local storage.
正解:A、C
解説:
MLflow training runs produce model artifacts - the serialized model files, conda environment, and MLmodel specification - stored in the run ' s outputs folder. These artifacts are transient run outputs but are not yet a versioned, named model that can be deployed. To make the model a first-class, versioned, deployable artifact, you must explicitly register it. Locating artifacts from the run (action A) is necessary because you need the run ' s artifact URI, typically in the form runs:/run_id/model, to register from.
Registering in the AML workspace (action B) creates an entry in the model registry with a name and auto- incremented version, making the model discoverable, governable, and deployable across environments.
Tagging the experiment (option C) does not version the model. Exporting to local storage (option D) removes the model from Azure ML ' s managed infrastructure, losing lineage and governance.
Microsoft Learn Reference Topic: Register MLflow models in the Azure Machine Learning model registry
質問 # 37
......
AI-300の学習教材は、テストの迅速な合格に役立ちます。認証を利用できます。多くの人が、AI-300試験問題の助けを借りて、日々の仕事でより効率的に行動する能力を向上させています。弊社のAI-300学習教材を選択すると、あなたの夢がより明確に提示されます。次に、私の紹介を通じて、AI-300学習クイズをより深く理解していただければ幸いです。 AI-300の学習教材が試験に合格するための手助けになることを本当に願っています。
AI-300独学書籍: https://jp.fast2test.com/AI-300-premium-file.html
Microsoft AI-300試験攻略 あなたは私たちを信頼し、将来の発展にあなたの忠実の仲間になることができます、Microsoft AI-300認定資格試験の難しさなので、我々サイトAI-300であなたに適当する認定資格試験問題集を見つけるし、本当の試験での試験問題の難しさを克服することができます、Microsoft AI-300試験攻略 彼らの標準、特にITワーカーの標準は、より高くなり、それは彼ら自身に高い要求を設定します、Fast2test AI-300独学書籍は、すべての候補者に最新と高品質の認定試験資材を提供する良いウェブサイトです、Fast2testのAI-300試験関連勉強資料はより良い勉強ガイドを提供し、お客様の学習効率を向上させることができます。
赤あか兵衛ひょうえはくびをかしげた、人々は今、そのような仕事はAI-300最高の警察ではないと感じています、あなたは私たちを信頼し、将来の発展にあなたの忠実の仲間になることができます、Microsoft AI-300認定資格試験の難しさなので、我々サイトAI-300であなたに適当する認定資格試験問題集を見つけるし、本当の試験での試験問題の難しさを克服することができます。
AI-300試験の準備方法|100%合格率のAI-300試験攻略試験|検証するOperationalizing Machine Learning and Generative AI Solutions独学書籍
彼らの標準、特にITワーカーの標準は、より高くなり、それは彼ら自身に高い要求を設定します、Fast2testは、すべての候補者に最新と高品質の認定試験資材を提供する良いウェブサイトです、Fast2testのAI-300試験関連勉強資料はより良い勉強ガイドを提供し、お客様の学習効率を向上させることができます。
- AI-300復習対策書 ???? AI-300無料模擬試験 ???? AI-300テスト難易度 ???? 【 www.copyright.jp 】を開き、▛ AI-300 ▟を入力して、無料でダウンロードしてくださいAI-300コンポーネント
- 無料PDFAI-300試験攻略 | 最初の試行で簡単に勉強して試験に合格する - 更新のAI-300: Operationalizing Machine Learning and Generative AI Solutions ???? サイト▷ www.goshiken.com ◁で⮆ AI-300 ⮄問題集をダウンロードAI-300テスト内容
- 真実なAI-300試験攻略 - www.jpshiken.com内の全て ???? { www.jpshiken.com }に移動し、✔ AI-300 ️✔️を検索して無料でダウンロードしてくださいAI-300無料問題
- 権威のある-効率的なAI-300試験攻略試験-試験の準備方法AI-300独学書籍 ???? 時間限定無料で使える《 AI-300 》の試験問題は➥ www.goshiken.com ????サイトで検索AI-300試験対応
- 権威のある-効率的なAI-300試験攻略試験-試験の準備方法AI-300独学書籍 ???? ウェブサイト➠ www.jpexam.com ????から⮆ AI-300 ⮄を開いて検索し、無料でダウンロードしてくださいAI-300テスト難易度
- AI-300日本語関連対策 ???? AI-300対応資料 ???? AI-300再テスト ???? ▛ AI-300 ▟の試験問題は“ www.goshiken.com ”で無料配信中AI-300日本語関連対策
- 完璧AI-300|ハイパスレートのAI-300試験攻略試験|試験の準備方法Operationalizing Machine Learning and Generative AI Solutions独学書籍 ???? ☀ www.xhs1991.com ️☀️を開いて( AI-300 )を検索し、試験資料を無料でダウンロードしてくださいAI-300テスト難易度
- AI-300対応資料 ???? AI-300試験復習 ???? AI-300無料模擬試験 ???? ウェブサイト⏩ www.goshiken.com ⏪から➤ AI-300 ⮘を開いて検索し、無料でダウンロードしてくださいAI-300トレーニング費用
- 無料PDFAI-300試験攻略 | 最初の試行で簡単に勉強して試験に合格する - 更新のAI-300: Operationalizing Machine Learning and Generative AI Solutions ???? 時間限定無料で使える「 AI-300 」の試験問題は[ www.copyright.jp ]サイトで検索AI-300ダウンロード
- AI-300テスト内容 ???? AI-300トレーニング資料 ???? AI-300コンポーネント ???? ▛ AI-300 ▟の試験問題は⏩ www.goshiken.com ⏪で無料配信中AI-300トレーニング費用
- 素敵なAI-300試験攻略一回合格-信頼的なAI-300独学書籍 ???? Open Webサイト▛ www.goshiken.com ▟検索☀ AI-300 ️☀️無料ダウンロードAI-300試験復習
- carlyzkpt098029.bloginder.com, socialrator.com, bookmarkmiracle.com, bookmarking1.com, uxtools.net, siobhanglos396063.illawiki.com, bookmarkpressure.com, www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, Disposable vapes